Monsternamekast
Capstone project for A.I. minor in collaboration with Brabantse Delta water authority. Our team devised a machine learning model predicting water inflow, crucial for optimizing the sampling frequency for the "monsternamekast" water samplers at treatment plants.
What exactly is a water sampler, and why does the sampling rate matter? A water sampler diligently collects water samples over a 24-hour period, allowing for subsequent analysis to assess water quality. The sampler takes a sample after every X cubic meter of water enters the treatment plant, a value set initially. A problem arises because the collected water must fall within the range of 5L to 55L to be accepted. Given the unpredictable nature of incoming water because of the big influence that rain has on this matter, predicting the inflow becomes necessary to set the sample rate accurately, ensuring each sample falls within the acceptable 5L to 55L range.
📌 Project specifications
- Goal:
-
Develop a machine learning model to predict the amount of water flowing to a purification plant based on the weather forecast over a period of 24 hours.
- Scope:
-
The project focused exclusively on the Riel area as a proof of concept, chosen for its smaller water infrastructure and data availability.
- Timeline:
-
20 Weeks
- 13 Weeks part-time (since we still had other minor lessons within this period)
- 7 Weeks full-time
🖥️ Technical Specifications
- Technologies, tools and frameworks used:
-
- Jupyter Notebook (with Python and relevant ML libraries)
- Shapefile extractor software
- Data:
-
The created dataset used for this project includes the following key components, which include both recieved data from the Brabantse Delta and independantly collected data:
- Weather forecast data (from WIWB)
- Rainfall data for the specified Riel area (from KNMI)
- Flow rate data from the pumps in the Riel area to the central facility
- Influent data representing the water entering the central facility
- Model architecture:
- During the theoretical exploration phase, various machine learning models were considered. The selected model which showed the biggest promise was a multi-step linear regression model, which made use of lag features to deal with the time-series data.
🎯 Results
The project achieved several milestones towards the final model, which accurately predicts the inflow to the central facility with an R-squared of 86%.
- Data Collection and Exploration: The first milestone involved finalizing the time-intensive data collection and exploration phase, addressing challenges related to the scarcity and complexity of the data.
- Model Selection: The second milestone encompassed the theoretical and experimental phase, where various machine learning models were explored and tested to determine their applicability.
- Final Predictive Model: The last milestone involved creating the ultimate predictive model. Numerous configurations of feature engineering were tested to develop the final model.
While the 86% R-squared for predicting inflow is notable, the true strength of the model becomes apparent when considering its application in configuring the water sampler. Even when the sample rate deviates slightly, the predicted inflow consistently remains close and stays within the predefined acceptable limits of 5L to 55L. This results in the model achieving a remarkable 100% accuracy in predicting inflow closely enough to always adhere to the water sampler's operational limits.

Image 1: "Monsternamekast" Water Sampler.
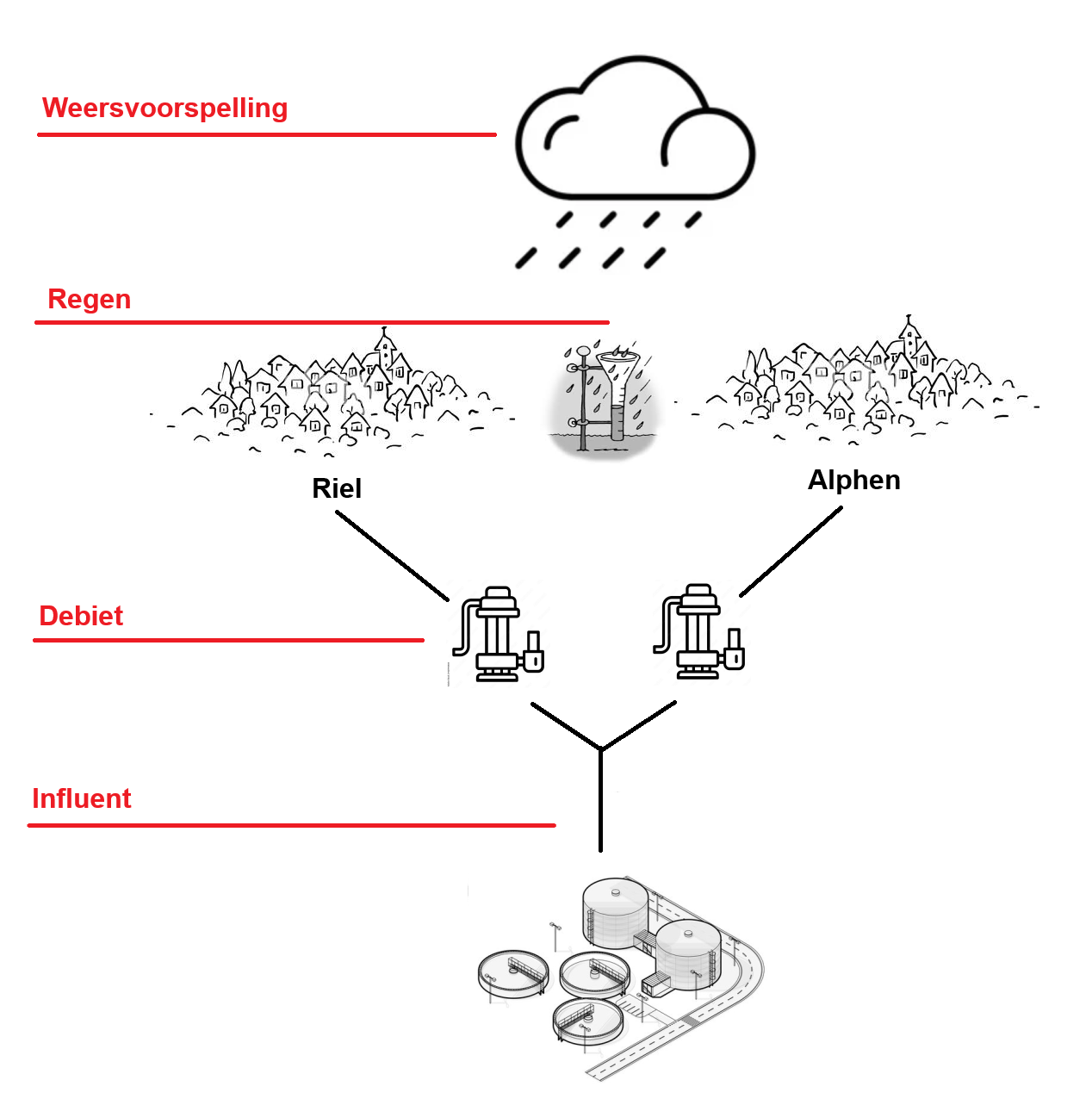
Image 2: An image of the available data sources for this project.
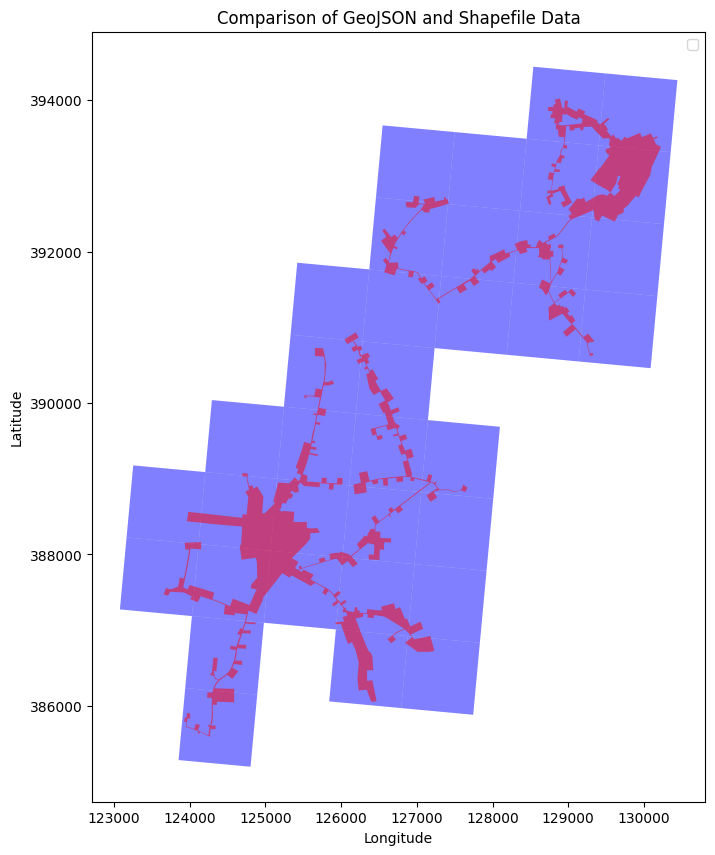
Image 3: An image of how we used shapefiles and geoJSON data to get rain data for the specific area of Riel.
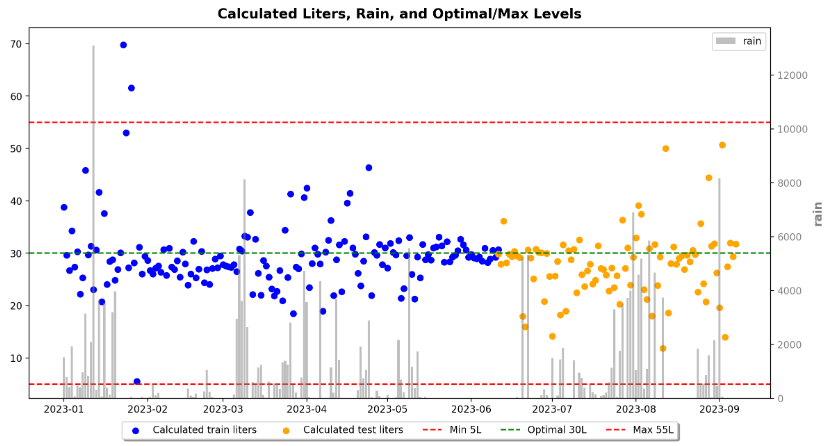
Image 4: Results of our final model. The blue data points are where the model was trained, whilst the orange ones show the model being tested.
💭 Reflection
Personally, I found immense satisfaction in working on this project, as it allowed me to engage in both theoretical exploration and hands-on development of a machine learning model with tangible real-world implications. A significant takeaway for me was the realization that in practical ML projects, a substantial portion—around 90%—is dedicated to data gathering and cleaning. The importance of quality data became evident, as without it, the model's performance is severely hindered. Additionally, this project reinforced the notion that simpler models often outperform more complex ones in real-world ML applications. Both our project and observations from other groups in the minor highlighted that straightforward models, such as linear regression and random forest, consistently yielded superior results despite their simplicity.